| .idea | ||
| .img | ||
| keyboard | ||
| model/en-us | ||
| pynput | ||
| .gitignore | ||
| changes.md | ||
| command.list | ||
| commandeditwnd.py | ||
| commandeditwnd.ui | ||
| keyactioneditwnd.py | ||
| keyactioneditwnd.ui | ||
| LICENSE.txt | ||
| main.py | ||
| mainwnd.ui | ||
| mouseactioneditwnd.py | ||
| mouseactioneditwnd.ui | ||
| pauseactioneditwnd.py | ||
| pauseactioneditwnd.ui | ||
| profileeditwnd.py | ||
| profileeditwnd.ui | ||
| profileexecutor.py | ||
| profiles.dat | ||
| README.md | ||
| set_kws_threshold.py | ||
| soundactioneditwnd.py | ||
| soundactioneditwnd.ui | ||
| soundfiles.py | ||
| ui_commandeditwnd.py | ||
| ui_keyactioneditwnd.py | ||
| ui_mainwnd.py | ||
| ui_mouseactioneditwnd.py | ||
| ui_pauseactioneditwnd.py | ||
| ui_profileeditwnd.py | ||
| ui_soundactioneditwnd.py | ||
LinVAM
Linux Voice Activated Macro
Status
This project is currently a work-in-progress and is minimally functional only for english.
Utilising Pocketsphinx, a lightweight voice to text engine you can specify voice commands for the tool to recognise and actions to perform.
Known bugs and planned additions
- To save and use changes click Ok on the main GUI then reload.
- Remember last loaded profile and load on start
- Log window showing spoken words the V2T recognises with ability to right click and assign voice command and actions to current profile
- Support for joysticks and gaming devices
Requirements
- python3
- PyQt5
- python3-xlib
- pyaudio
- pocketsphinx
- swig3.0
Optional requirements
- xdotool
- ffplay (part of ffmpeg, usually already installed)
- HCS voicepacks
Install
- $ pip3 install PyQt5
- $ pip3 install python3-xlib
- $ pip3 install pyaudio
- $ pip3 install pocketsphinx
- $ sudo apt-get install swig3.0
- $ (optional) sudo apt install xdotool
- $ (optional) sudo apt install ffmpeg
- $ sudo ln -s /usr/bin/swig3.0 /usr/bin/swig
- $ git clone https://github.com/aidygus/LinVAM.git
Usage
This script must be run with root privilege because it must hook and simulate input devices such as keyboard, mouse etc.
- $ cd LinVAM
- $ xhost +
- $ sudo ./main.py
As an alternative, if you use the X window manager and have xdotool installed, you can run the script like this:
- $ cd LinVAM
- $ ./main.py -noroot
Profiles
Multiple profiles are supported. To create a new profile for a specific task/game click new and the main profile editor window will be displayed
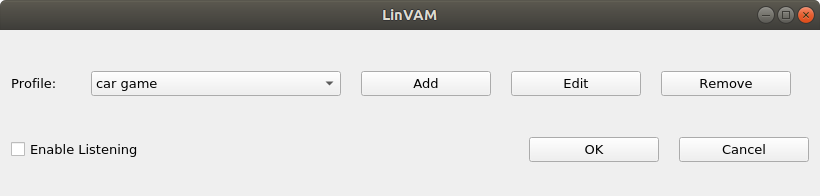
Key combinations
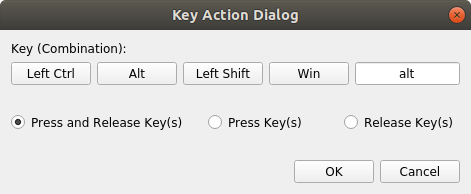
To assign key combinations first decide which functional key to press by clicking on Ctrl, Alt, Shift or Win to denote left or right key then press the actual command key
Complex commands
It is possible to add multiple actions to a voice command for complex macros with the ability to add a pause between each action. You can also assign mouse movements and system commands if you require (eg opening applications such as calculator, browser etc)
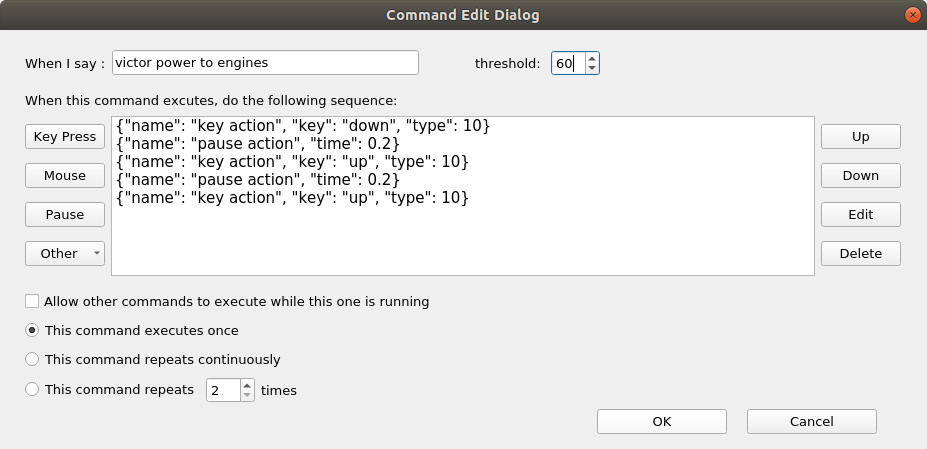
Threshold
As a rough guide use a value of 10 for each syllable of a word then tweak it down for better accuracy.
Output audio
In the Command Edit Dialog, chose 'Other' and then 'Play sound'. Pick the sound you would like to play. For this to work you need to copy any audio file you would like to use to the folder 'voicepacks'. You are required to create a subfolder to hold all your audio files (voicepack folder), then within that subfolder, create as many folders as you like to group your audio files (category folders). Place the audio file into these category folders or in any subfolder within a category folder. In theory any audio file should work, but tested only with MP3 files.
Example: /voicepacks/my voicepack/custom commands/hello.mp3 /voicepacks/my voicepack/other/thank you.mp3
If you own a HCS voicepack, copy the whole voicepack folder (like 'hcspack', 'hcspack-eden', ...) to the 'voicepacks' folder, so it reads like this: /voicepacks/hcspack/...
Improve voice recognition accuracy
Please see this resource on how to train the acoustic model of pocketsphinx to match your voice: https://cmusphinx.github.io/wiki/tutorialadapt/